



 Deutschland
Deutschland India
India Lietuva
Lietuva United Kingdom
United Kingdom Search
Search Search
Search
.jpg?la=en&h=720&w=720&hash=832FEE385357F88B168D87208EBCD08E "Keeping Score on Customer Risk? Statistical Inference-based Models Can Better Keep Bad Actors off the Field")
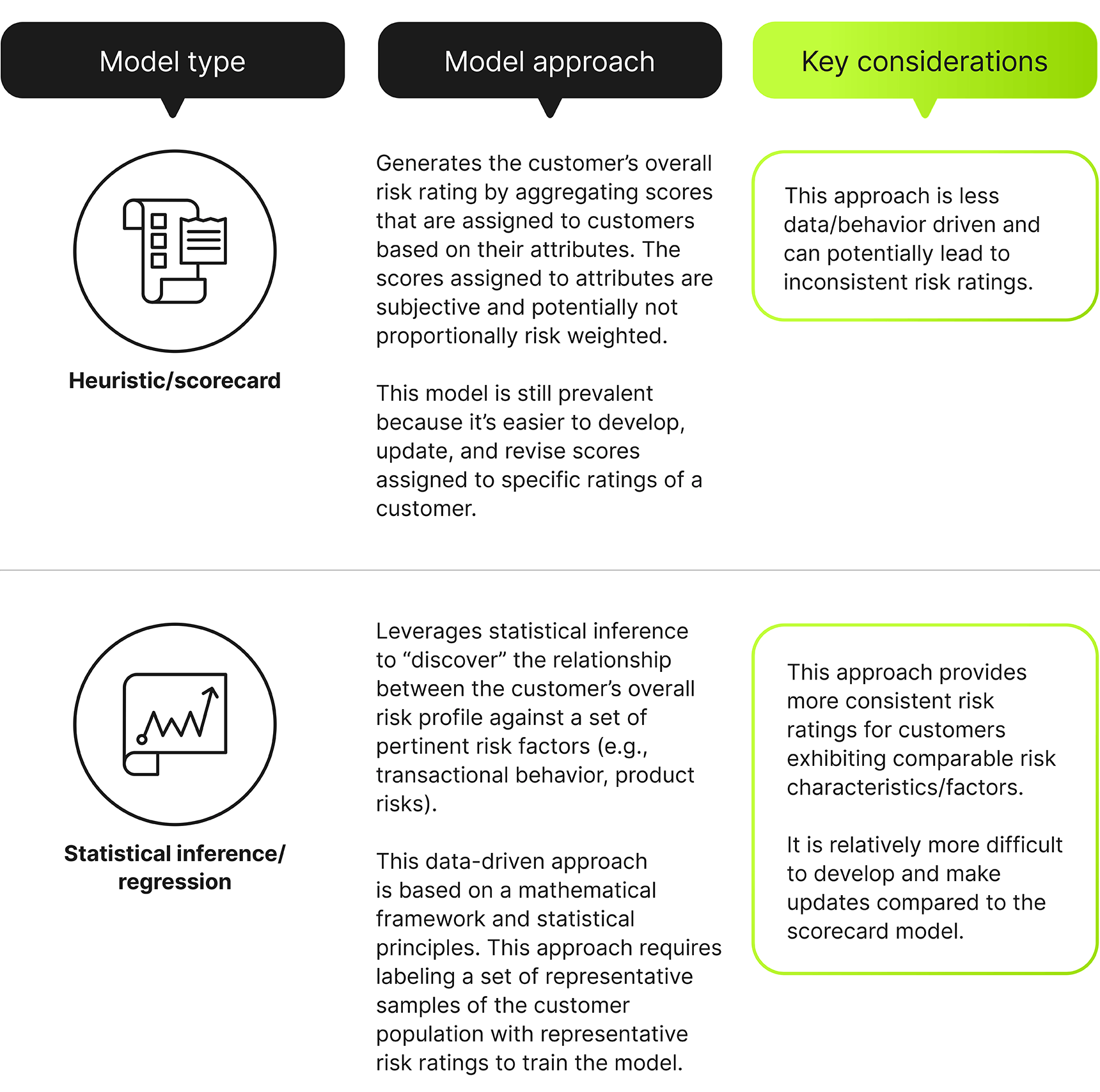
Customer risk rating (CRR) should be a key component of any financial institution’s risk management strategy. While many institutions continue to rely on the traditional scorecard model, they may end up inconsistently assessing customer risk based on subjectively determined scores. Forward-looking institutions are developing regression models, which attempt to remove this subjectivity from the customer’s risk rating. By processing data through a mathematical framework and generating the expected (i.e., “wide-lens” view) rating of the customers based on a broad set of risks, subjectivity is reduced in the customer risk assignment process.
Customers should be risk rated during the onboarding process, at regular intervals, and when significant risk events occur (such as filing a suspicious activity report, or SAR). CRR models estimate a customer’s overall risk (e.g., “low”) based on customer profile and relationship information, the products (e.g., brokerage account, home mortgage), and services (remote deposit, check writing, etc.) it partakes in, and its geographic footprint and transactional behavior.
Risk Factors
For both approaches, data provided to the model should represent financial institutions’ risk exposure in a broad and meaningful way. For example, the risks that are too niche to apply to a large enough customer footprint should be incorporated into a reasonably similar risk that has wider applicability. The type of risks captured by the model should also be informed by the type of customer that is being rated. For example, an “alternative-investment” customer might require evaluating different sets of risks from those of a “business entity” customer. The combination of these two considerations gives the model the ability to be both reasonably accurate while also covering general risks.
Domain knowledge (qualitative expert judgment) is leveraged to properly classify required information when developing a defensible model. Quantitative analysis determines how to optimize the information content of the risk factors, identifying a small set of risk factors that collectively have the maximum possible inference power.
Labels
In the regression approach, the model must be trained by “labeled” data. The label is assigned by subject-matter experts (SMEs) based on the qualitative assessment of a representative set of customers. The subjectivity of this process can be lessened through these best practices:
Complexity Kills Ability to Understand Model and Outputs
The objective of the CRR model is to “infer” the customer’s overall risk rather than “predict” it. This distinction, as well as the business and compliance requirement for model transparency and interpretability, should dictate model complexity. The interpretability requirement dictates that:
The first requirement can be achieved by consolidating similar attributes; this would reduce the number of predictors and improve the applicability of the predictors, which would produce a model with enhanced generality.
The selection of an appropriate modeling approach, such as a regression model, which explicitly requires the relationship between the predictors and the outcome to be estimated, satisfies the second requirement.
Institutions that continue to operate on traditional models potentially expose themselves to inconsistent risk rating of their customers. While migrating to a statistical inference model can present challenges such as generating labels (qualitative assessment of a representative sample of customers) or incorporating new risk factors, the ability to remove subjectivity from customer risk ratings enhances the interpretability of the risk rating and imparts consistency to the process. The statistical inference approach produces an effective and sound model that meets the interpretability, transparency, simplicity, and coherence requirements.
Guidehouse is a global AI-led professional services firm delivering advisory, technology, and managed services to the commercial and government sectors. With an integrated business technology approach, Guidehouse drives efficiency and resilience in the healthcare, financial services, energy, infrastructure, and national security markets.